Open INESEM
Investigación

Diseño e implementación de un Datawarehouse en una cadena de tintorerías y lavanderías
1. Introducción
El desarrollo del proyecto se ha orientado hacia la generación de un datawarehouse para el análisis de los actuales sistemas de información y la posterior implantación de una solución de inteligencia de negocio para aportar mayor conocimiento del negocio, control sobre los procesos y ampliar la capacidad y calidad de la toma de decisiones de los directivos.
Actualmente la empresa carece de un sistema de Business Intelligence, se hace uso de ficheros Excel dispersos en discos con datos extraídos de los sistemas transaccionales y se confeccionan periódicamente informes de facturación y servicios.
Desde sus inicios la empresa desarrolló su propio software, consiste en un TPV localizado en cada establecimiento y un sistema con el que copia los datos locales de las tiendas en un servidor central.
La explotación de estas bases de datos se hace mediante una serie de procedimientos almacenados generados por un experto en bases de datos.
2. Evaluación y diagnóstico de necesidades
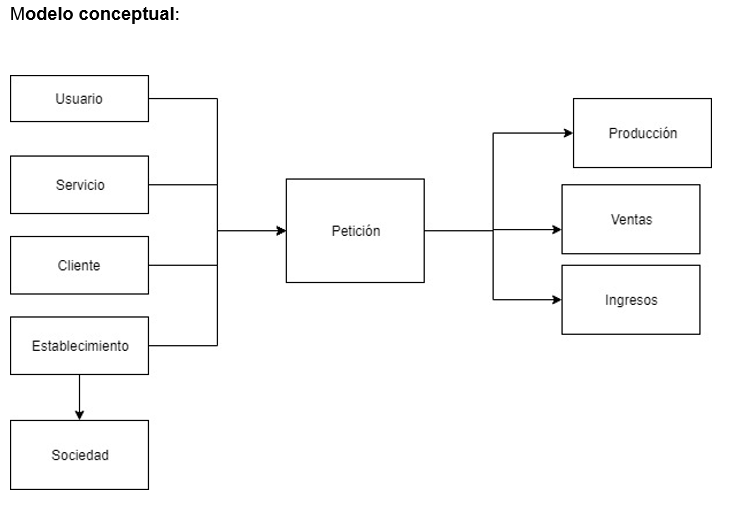
Actualmente no existe ningún Datawarehouse, se realizan reuniones con los departamentos para conocer que esperan obtener del sistema. De estas reuniones obtenemos el diseño conceptual.
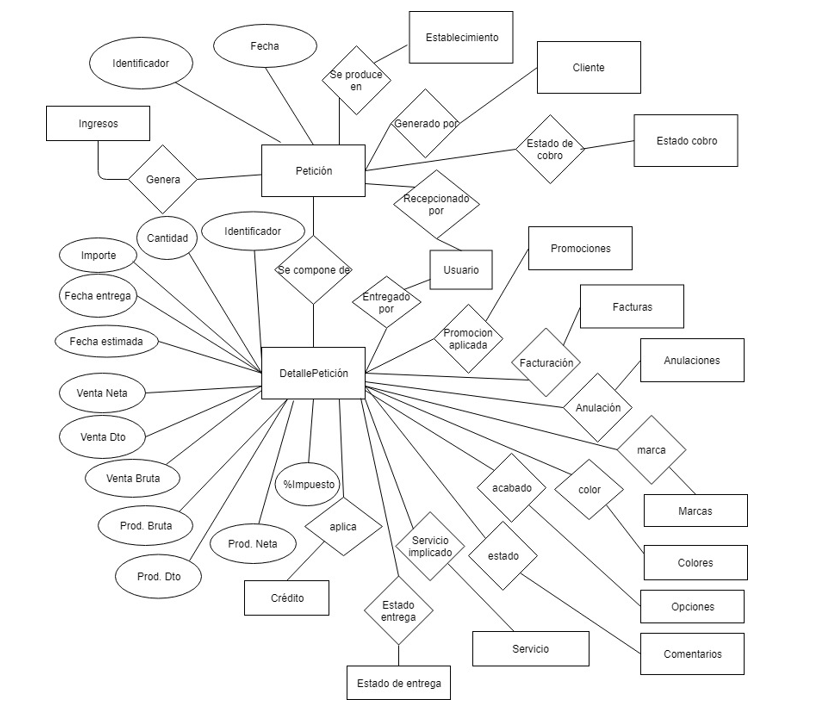
El desencadenante del proceso es la petición, se produce cuando un cliente lleva sus prendas al establecimiento para ser procesadas. A partir de esta premisa surgen las siguientes entidades:
- Sociedad: propietario del establecimiento
- Establecimiento: lugar dónde se producen la petición
- Cliente: persona que requiere del servicio
- Empleado: persona que procesa el servicio
- Servicio: artículo sobre el que se realiza la acción
Sobre estas entidades se generan:
- Ingresos: cantidad que se cobra por el servicio.
- Producción: valor del servicio.
- Venta: importe de la transacción.
La diferencia entre la producción y la venta está en ciertos productos promocionales.
3. Formulación de objetivos
El modelo lógico lo vamos a desarrollar entidad a entidad y desarrollándola.
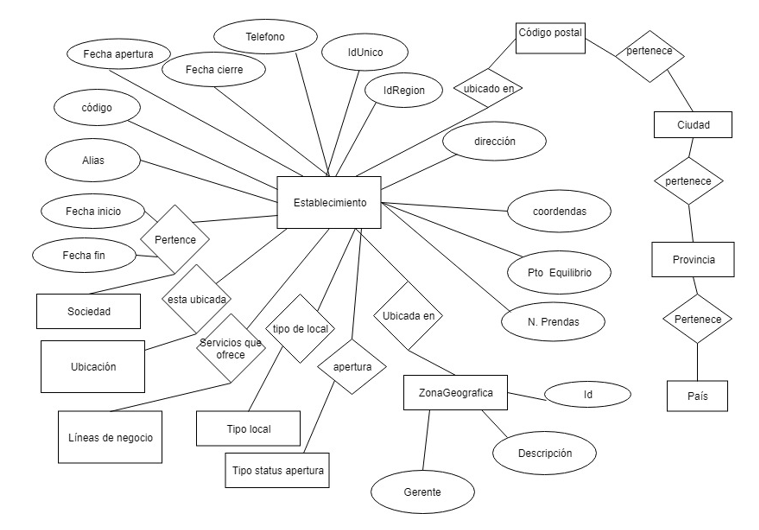
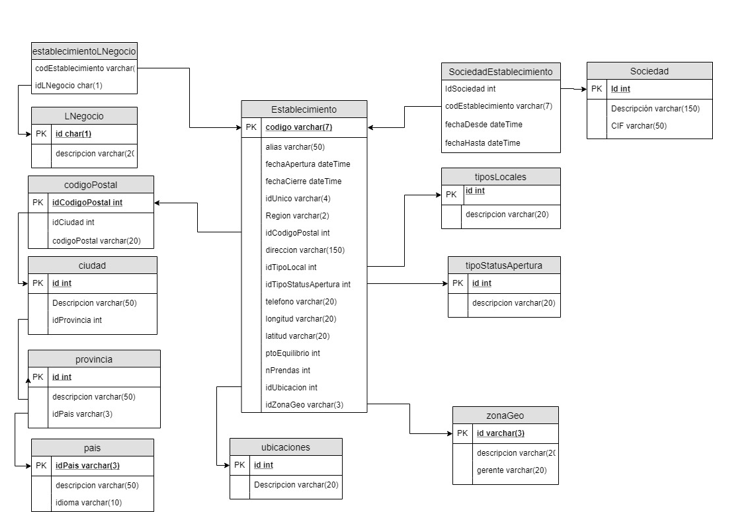
Establecimiento: lugar dónde se produce la petición:
Usuario: realiza dos acciones recepción y entrega.
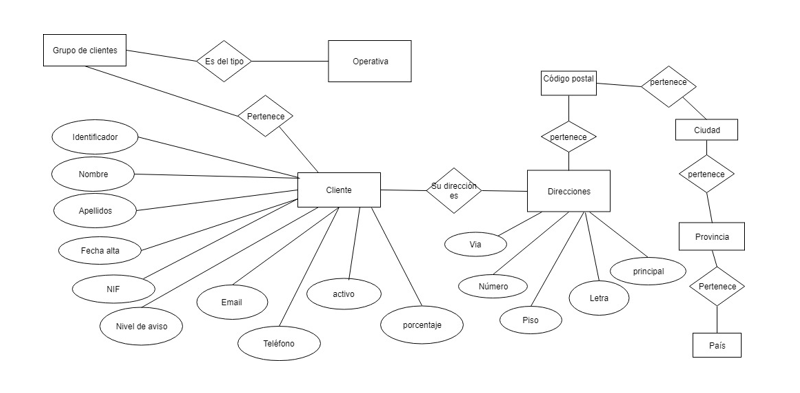
Cliente: propietario del servicio.
Servicio: el ítem que se genera la transacción
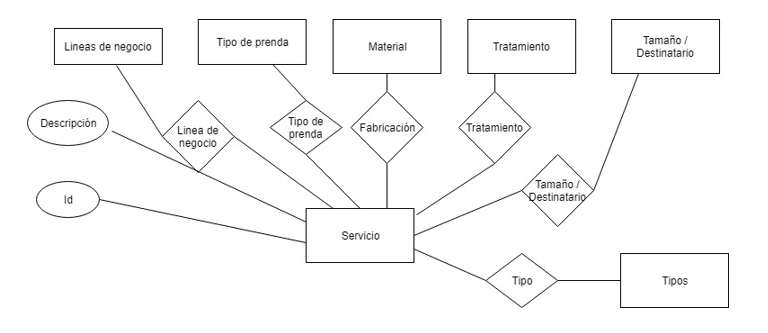
Petición:
El servicio que se presta al cliente en una tienda por el usuario. El cliente puede llevar varias prendas, que pueden entregarse en fechas diferentes, por usuarios diferentes y tener asociados distintos comentarios, colores, marcas.
La petición se divide en dos, tenemos la petición, todos los campos son comunes a todos los servicios y el detalle de la petición, los campos son diferentes por cada servicio.
Aquí nos encontramos con otras cinco entidades:
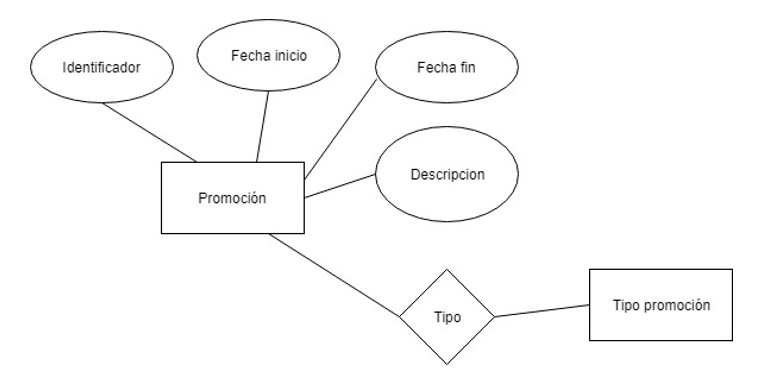
Promoción / descuento
Promociones que se pueden aplicar a un servicio:
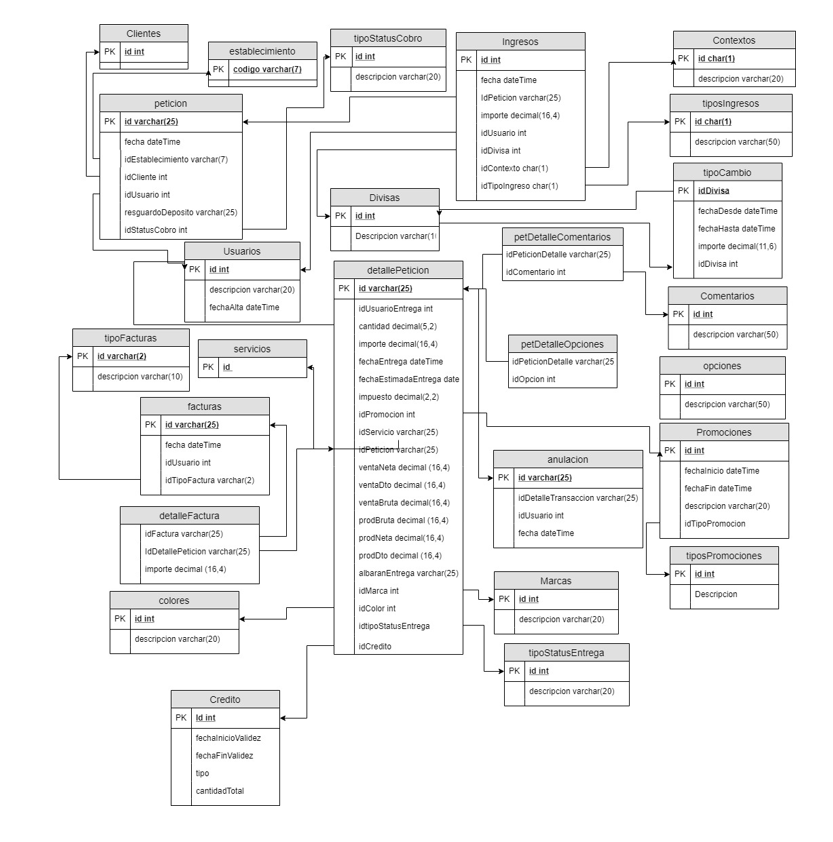
Ingreso: Cobros generados por la petición, se puede generar en la recepción o entrega o a posterior y puede corresponder a parte o al total de la petición. No tiene por qué corresponder con el detalle de la petición.
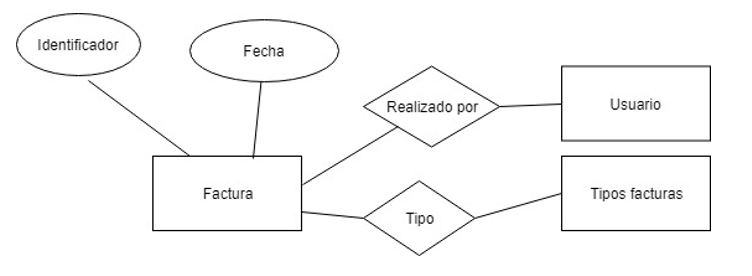
Factura:
Anulaciones: puede corresponder con el total de una petición o sólo con parte de su detalle, se decide gestionarla de forma separada ya que la relación es mínima.
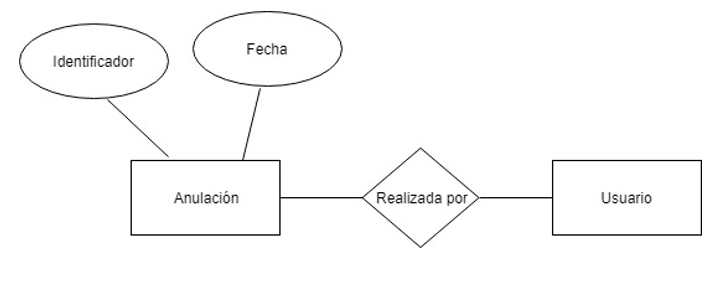
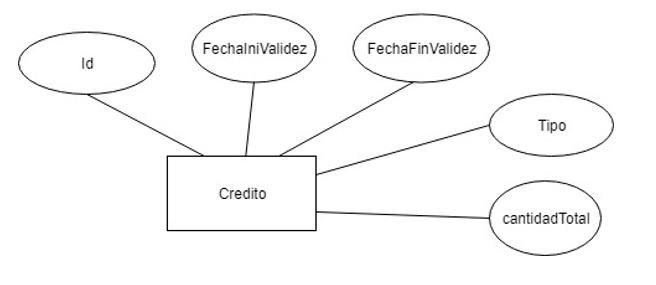
Créditos: Existen varios medios promocionales que generan crédito, nos interesa estudiarlos para ver la rentabilidad.
Una vez vistas todas las entidades la relación entre ellas serian la petición y el detalle de la petición.
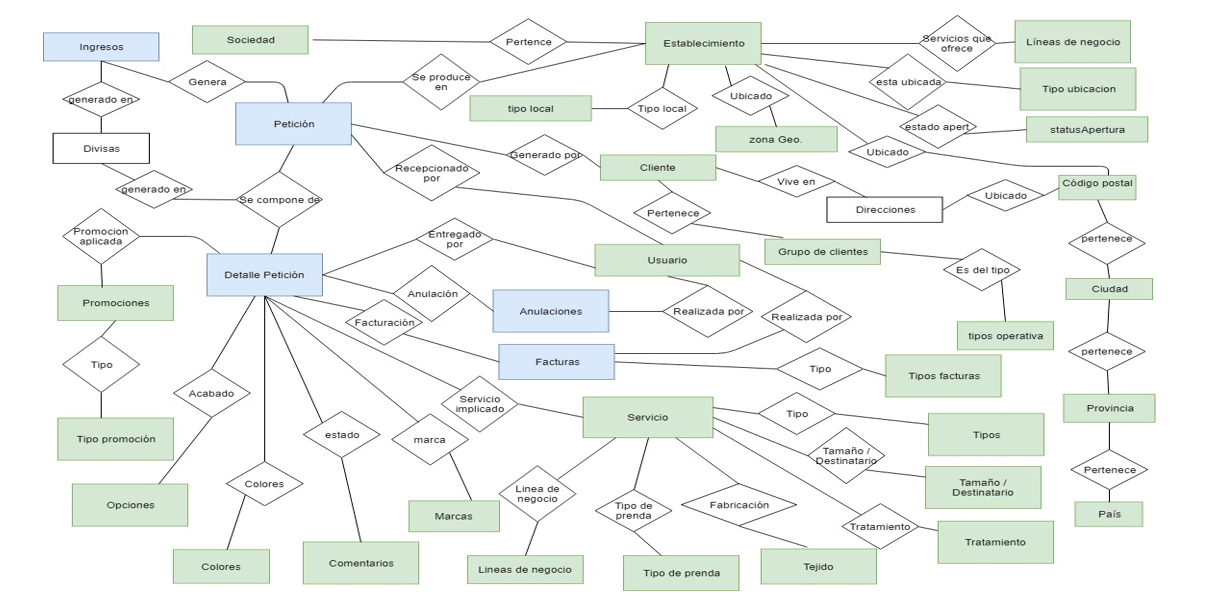
El modelo lógico: se omiten los atributos, se marcan en azul las entidades que serán las dimensiones y en verde los hechos.
El modelo físico, usaremos el gestor de base de datos MySQL, esta plataforma se está usando para otros servicios y no habría que invertir en más recursos.
Establecimiento
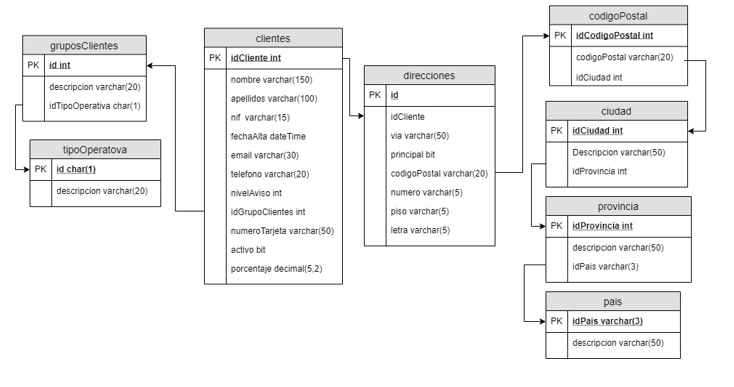
Clientes
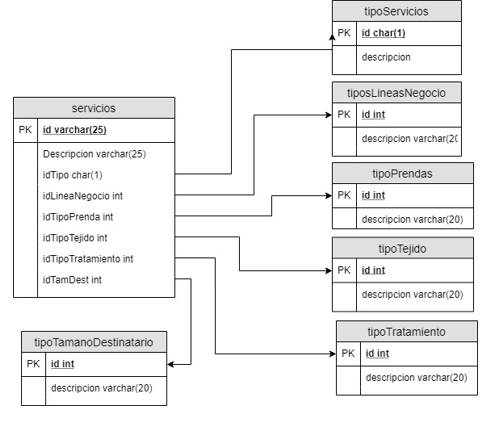
Servicios
El modelo físico para las demás entidades sería:
Creamos varias tablas relativas a las fechas para estudiar la información en base a periodos de tiempo.
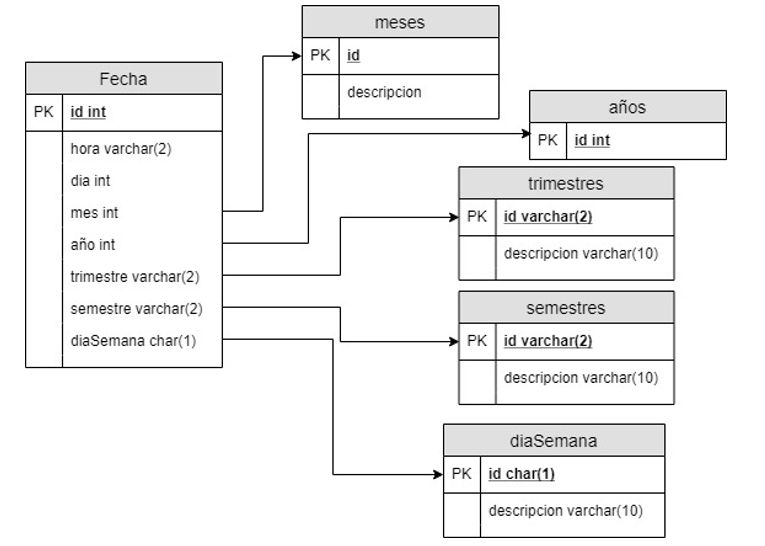
Cambiamos los campos que actualmente son DateTime a int y los relacionamos con la tabla fecha.
4. Propuesta de intervención
Una vez definido el modelo físico se genera la base de datos creada para este fin.
En cada establecimiento reside una base de datos local en SQL Server 2008 express R2, estas son independientes, por lo que hay información repetida en varias de estas bases de datos.
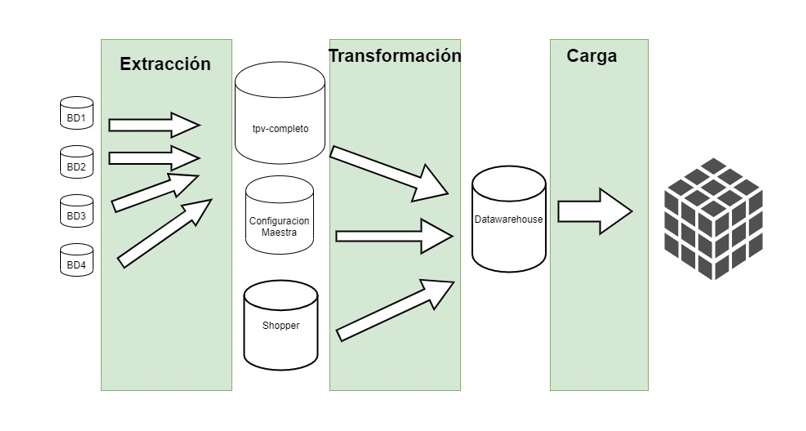
Dividimos el proceso ETL en tres fases:
- Extracción: las bases de datos de los establecimientos se replican a un servidor central de la empresa, generamos una base de datos que se rellenará con toda la información de la base de datos del establecimiento sin procesar.
- Transformación: desde tpv-completo (datos en bruto) y Shopper (datos de los establecimientos) vamos a transformar los datos y almacenarlos en una base de datos dónde estén procesados (datawarehouse)
- Carga: con los datos procesados se van a generar los cubos que usaremos para estudiar la información.
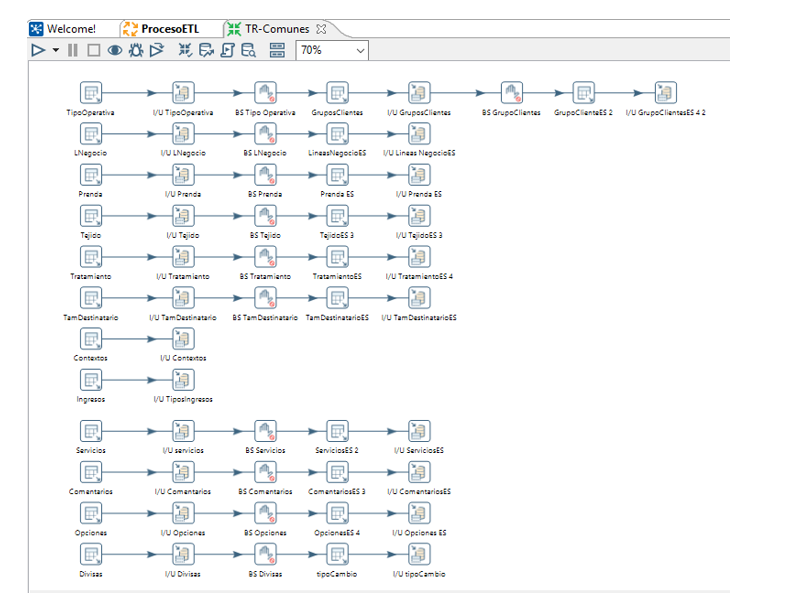
Utilizaremos el programa pentaho data integration para realizar todo el proceso. Creamos el JOB principal “Proceso ETL”, crearemos transformaciones para cada uno de los procesos, esto facilitará el diseño y posibles problemas que puedan surgir.
Comenzamos con la extracción de los datos desde las bases de datos de los establecimientos a la base de datos tpv-completa.
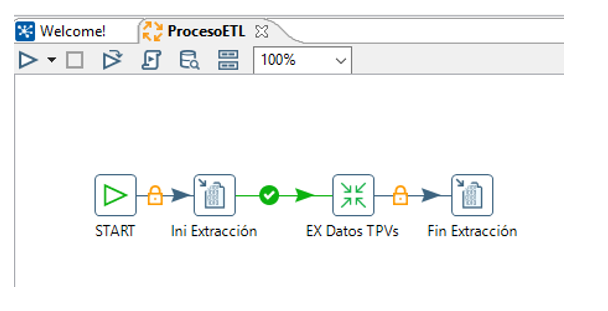
Proceso de extracción
Estudiando las bases de datos vemos que existen diferentes esquemas. La diferencia es incremental.
Comenzamos generando una base de datos, tpvCompleto, con la estructura más actual añadiendo el código del establecimiento y un campo que indique si ha sido procesado. También generamos una tabla para indicar la última carga de cada tienda, nos servirá para cargar sólo los datos faltantes o que hayan sido modificados.
Existe una base de datos llamada Central con la tabla tiendas, dónde se almacena la fecha de ultimo envío de datos desde el establecimiento a la central y la versión del esquema de la base de datos, la vamos a utilizar para cargar tiendas de las que faltan datos.
La primera transformación es la extracción de datos desde las bases de datos de los establecimientos hacia la base de datos “tpvcompleta”
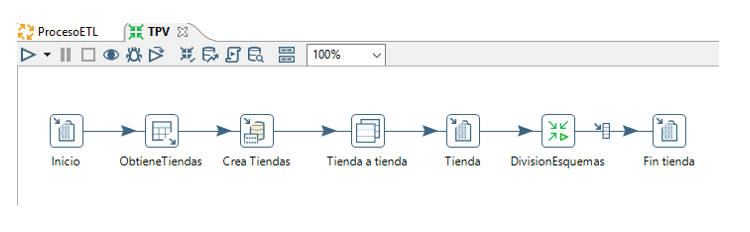
Para cada establecimiento, la transformación DivisionEsquemas, obtiene la fecha hasta la que hay datos en la base de datos tpv-completa, si no hay datos de esa tienda por defecto se aplica la fecha ‘01/01/1990’.
En base a la versión que tiene del sistema tpv va llamando a diferentes transformaciones para generar la carga de las tablas. Para finalizar actualiza la fecha desde la que hay datos en la tabla tiendas de la base de datos tpv-completo.
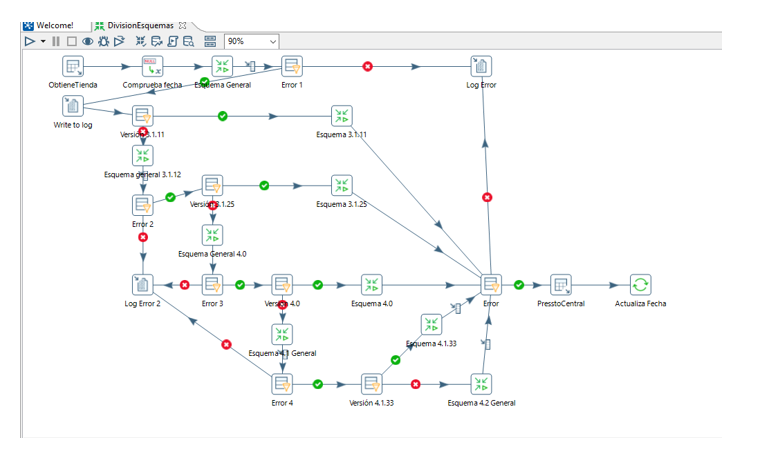
Las transformaciones: por cada tabla se obtienen los datos a partir de la fecha anterior y se usa la opción de actualizar o insertar.
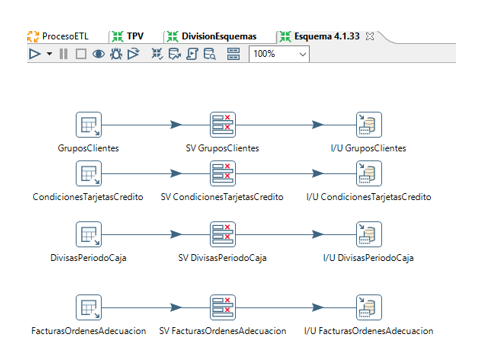
Una vez hemos finalizado la parte de extracción pasamos a la fase de transformación.
Proceso de transformación
Vamos a generar dos procedimientos en la base de datos datawarehouse para generar los datos de las tablas relacionas con las fechas.
El primero es RellenaAuxFecha que rellena las tablas dm_Mes, dm_Trimestre, dm_Semestre y dm_diaSemana con los datos correspondientes. Este procedimiento sólo es necesario ejecutarlo una vez.
El segundo es GeneraFechas que rellena la tabla dm_fechas, con los valores comprendidos entre dos fechas que se le pasan cómo parámetro. De momento vamos a ejecutarlo desde 01/01/1990 hasta el 31/12/2020.
Comenzamos con la entidad establecimiento, ya que todo lo referente a esta entidad se encuentra en la base de datos Merchantdatabase.
Generamos una transformación “TR-Merchantdatabase” que añadimos a nuestro job
principal:
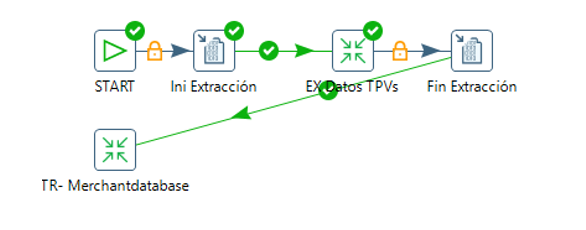
La primera parte de la transformación obtiene los datos de las tablas que no necesitan ningún procesamiento.
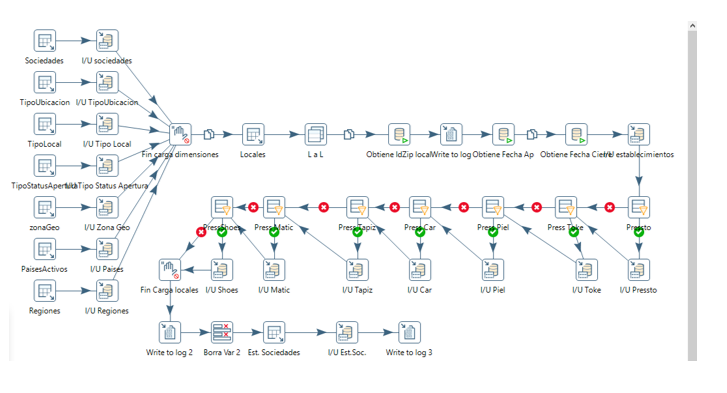
Después obtenemos todos los establecimientos, para cada uno de ellos:
1 – Se obtienen los códigos postales, ciudades y provincias de España desde la web https://postal.cat/ y se han precargado en la base de datos datawarehouse.
Los datos de las direcciones son escritas por el usuario, por lo que pueden llevar faltas ortográficas o ser incorrectos. Se ha creado una tabla auxiliar, dónde se hace una correspondencia entre el dato incorrecto y el correcto

2- Se ha creado otra función (obtenerFecha) en la base de datos que en base a una fecha devuelve el id de la tabla dm_fechas.
3 – Para cada una de las líneas de negocio disponibles se comprueba si el establecimiento la tiene y se inserta o borra de la tabla establecimientoLNegocio.
4 - Se obtiene la relación entre los establecimientos y las sociedades y se actualiza la tabla sociedadEstablecimiento
TPV-Completo
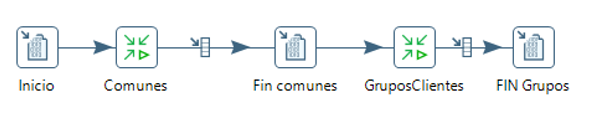
Desde la base de datos generada en el paso de extracción cargamos entidad a entidad. Creamos una transformación (TR-BasesDatosEstablecimientos) que ira llamando a diferentes transformaciones para obtener los datos de cada entidad
Configuración Maestra
Existe una base de datos ConfiguracionMaestra, aquí está la información base de algunas de las entidades.
Algunas de estas entidades se pueden cargar directamente desde esta base de datos ya que todos los datos que contiene son comunes.
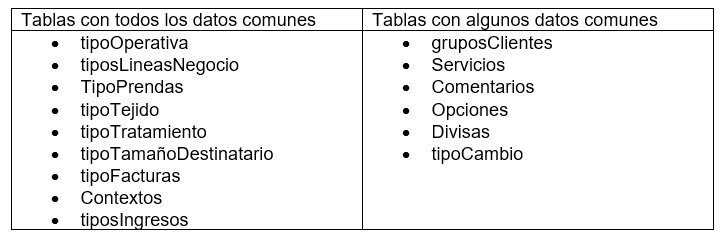
Añadimos esta transformación a nuestra transformación:
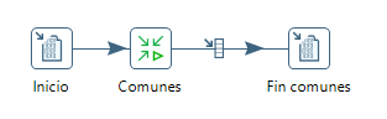
Entidad clientes
Las bases de datos son independientes por lo que existen datos repetidos en todas ellas, en todas las entidades vamos a ir creando tablas auxiliares para almacenar el id en la base de datos Datawarehouse y el id en la tabla de la base de datos. De esta forma vamos a ir limpiando los datos que vamos a traspasar al Datawarehouse.
El proceso es el siguiente:
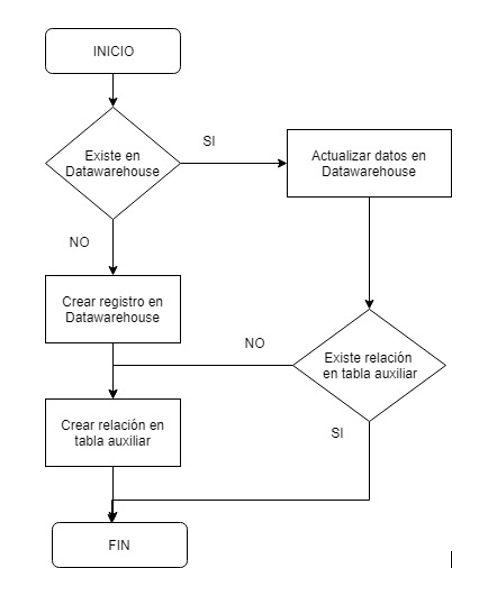
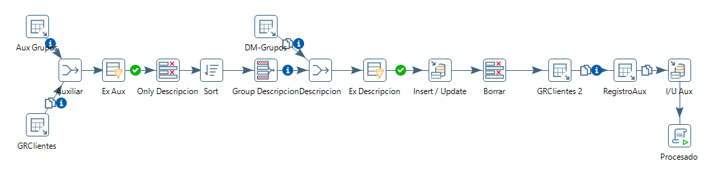
Añadimos esta transformación a la principal
Un cliente puede existir en varias tiendas, también hay que tener en cuenta que los usuarios pueden escribir los nombres de diferentes formas, con abreviaturas, nombres compuestos, etc. Vamos a tomar el NIF como el campo que va a determinar si el cliente existe o es nuevo. Decidimos hacer una función en la base de datos de Datawarehouse que compruebe si existe un cliente con ese NIF.

Unimos la nueva trasformación a la principal

Entidad Servicios
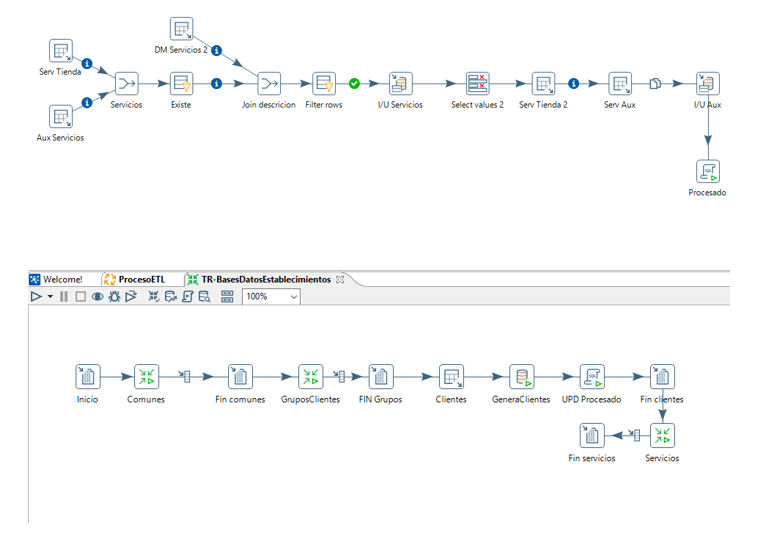
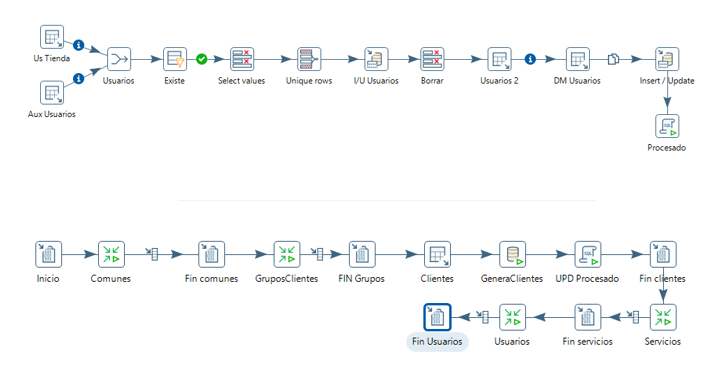
Entidad usuarios
La tabla usuarios tendrá una auxiliar pero que se rellenará manualmente ya que no hay forma de igualar el nombre entre tiendas.
Entidad promociones
Las promociones que se repiten entre tiendas se configuran desde la central y tienen el mismo código que será el que se use para su carga.
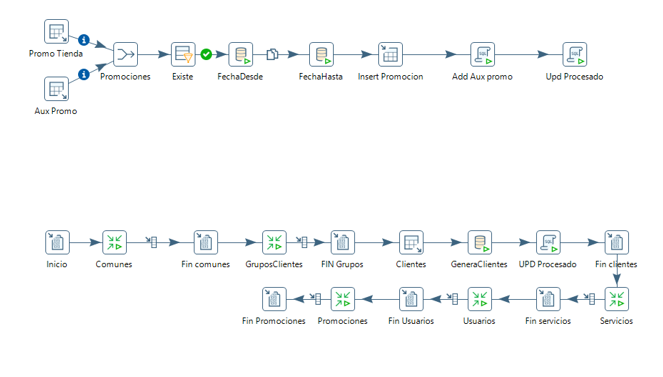
Entidad comentarios y opciones
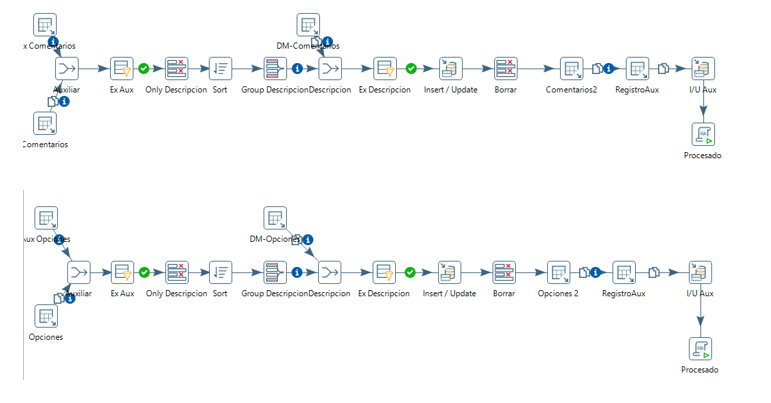
Añadimos las dos transformaciones a la principal
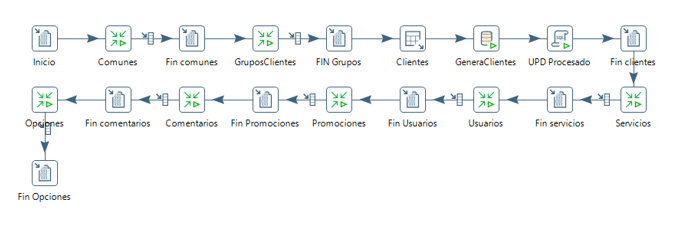
Entidad marcas
Para la entidad marcas vamos a crear un listado base accediendo a la web de El Corte Inglés y copiando las marcas con las que ellos trabajan. Esta entidad no tiene una tabla con los datos en TPVcompleto, es un campo texto que lo rellena el usuario en el alta de un servicio, por lo que la cargaremos a la vez que el detalle de la petición.
Creamos una tabla auxiliar para hacer corresponder las marcas precargadas con las escritas por el usuario.
Entidad colores
Con los colores hacemos lo mismo que con las marcas, descargamos un listado de colores desde internet.
Creamos una tabla auxiliar para hacer corresponder los colores precargados con los escritos por el usuario.
Entidad peticiones y detallePeticiones
Para las entidades petición y detallePeticion vamos a tomar petición a petición e ir calculando el detalle y las demás entidades relacionadas.
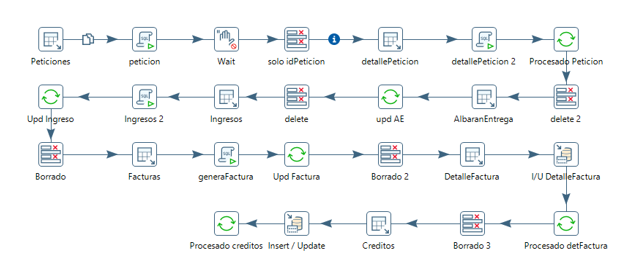
Lo unimos al proceso principal
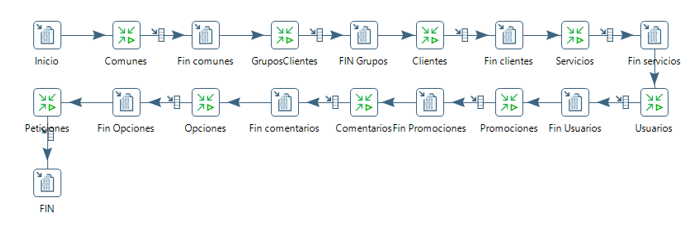
Proceso de carga
Tenemos constancia de que los usuarios son inexpertos en estas materias por lo que vamos a comenzar generando varios cubos sencillos, que se irán ampliando según el usuario lo requiera.
Para diseñar los cubos vamos a usar la aplicación schema-workbench de pentaho.
Los tres cubos a generar son:
- Ventas:
- la tabla de hechos es detallePetición
- Dimensiones
- Usuario entrega
- Fecha de entrega
- Promociones
- Servicios
- Marca
- Color
- Medidas
- Venta neta
- Venta bruta
- Venta descuento
- Numero de servicios
- Producción bruta
- Producción neta
- Producción descuentos
- Peticiones
- La tabla de hechos es peticiones
- Dimensiones
- Fecha
- Establecimiento
- Cliente
- Usuario
- Medidas
- Numero de recepciones
- Ingresos
- Tabla de hechos ingresos
- Dimensiones
- Usuario
- Contexto
- Tipo de ingreso
- Fecha
- Medidas
- Ingresos
- Dimensiones
- Tabla de hechos ingresos
5. Delimitación de recursos
Para comenzar la implantación necesitaremos de un servidor con capacidad suficiente para almacenar y gestionar tanta información, se necesitan dos bases de datos:
- tpvCompleto: se calcula que es necesario 100Mb por cada año y tienda, actualmente la media de Pressto son 10 años y son entorno a 400 bases de datos:
100Mb * 10 años * 400 establecimientos = 400.000 Mb = 390 Gb
- datawarehouse: esta base de datos al ser nueva no se tiene tanta información, pero se calcula que está entorno a los 300Mb por año:
300Mb * 10 años = 3000 Mb = 3 Gb
Se decide usar dos servidores uno en el que albergar la base de datos de tpvCompleto y otro en la que estará la instalación de pentaho con base de datos Datawarehouse, Mondrian con los cubos y todos los informes que se generarán en base a toda esta información.
Se decide realizar una serie de reuniones para explicar que es un datawarehouse y cómo se ha gestionado. Estas reuniones también se utilizarán para que los usuarios tomen contacto y sean capaces de generar los informes y cuadros de mando que cada uno de ellos requiere.
Actualmente sólo se cuenta con uno de los servidores el que alberga tpvCompleto. Por lo que los pasos para iniciar la implantación en este servidor son:
- Crear la base de datos tpvCompleto con el script que hemos obtenido anteriormente.
- Tener acceso a las réplicas de las bases de datos que tenemos en el servidor de Pressto para obtener toda la información que se va a cargar en tpvCompleto
- Configurar Pentaho (que estará en el segundo servidor) para que una vez al día ejecute el Job principal que hemos generado anteriormente para que se obtengan los datos
Una vez que el primer servidor esté en marcha y funcionando correctamente, pasaremos al segundo.
El segundo servidor los pasos serían los siguientes:
- 1Crear la base de datos Datawarehouse con el script que hemos creado.
- Instalar Pentaho
- Generar los cubos y publicarlos en Pentaho
6. Seguimiento, control y valoración de resultados
Tal y como se ha comentado anteriormente los usuarios son inexpertos en este tipo de tecnologías, por lo que se ha comenzado con algo sencillo para que puedan ir familiarizándose.
El éxito de este proyecto radica sobre todo en ser capaces de que los usuarios vean el valor que aporta una solución de Business Intelligence, para posteriormente aplicar sistemas de Big Data.
Se plantea la necesidad de implantar unos cursos básicos para comprender que es esta herramienta, para que sirve y los beneficios que tiene. Se van a llevar a cabo en tres grupos uno para la dirección, segundo para los mandos intermedios y finalmente para el personal más operativo
Una vez superada y puesta en marcha esta primera fase hay que ir incluyendo los datos de los demás sistemas que usa la empresa en el datawarehouse. De forma que consigamos un sistema dónde poder ver la información completa de toda la empresa, además de generar los cuadros de mando requeridos por cada nivel jerárquico de esta.
7. Conclusiones
Desde mi posición en esta empresa este trabajo de fin de máster me ha supuesto un gran reto, ya no sólo por la implantación de toda la materia que he aprendido a lo largo del máster. Mi mayor reto ha sido y sigue siendo el usuario final, como hacerle entender desde su punto de vista que supone un sistema de Business Intelligence y Big Data.
Partiendo de la base que actualmente no hay ningún sistema de estas características en la empresa, es complicado hacer ver al usuario final que todo el tiempo invertido va a repercutir en una aplicación que les va a dar muchísima información de forma fácil y dinámica. Actualmente tienen parte de esta información, pero no es al momento y requieren que un experto en bases de datos genere los informes requeridos y se lo envíe.
Otra de las reticencias con los usuarios es el tiempo que se tarda en implementar hasta que ellos pueden ver el resultado. Cuando se realiza un proyecto de este tipo el mayor tiempo se invierte en el diseño y el proceso ETL, en esas fases el usuario final no es capaz de ver la envergadura ni el resultado que va a obtener. Hasta la última fase que es cuando se publican los cubos y ya ellos pueden empezar a trabajar con la información el usuario no puede ver el beneficio que le supone este tipo de sistema.
Referencias
Bouman, Roland y van Dongen, Jos (2009). Pentaho solutions: Business intelligence and Data Warehousing with Pentaho and MySQL. Wiley
Urrutia Sepulveda. Angélica (2013). Implementación de Business Intelligence en plataforma Free de Pentaho: Aplicaciones en Posgree, Weka y Kettle. EAE
Hitachi Vantara Corporation. Pentaho community fórums (https://forums.pentaho.com/)
Javier Casares (1 enero 2019). Base de datos de Códigos Postales. https://postal.cat/
El Corte Inglés. Marcas de Moda. https://www.elcorteingles.es/moda/marcas/
